






Why Memory Stocks Crashed Today: TurboQuant Just Changed The Game With “Google’s DeepSeek Moment”
With stocks closing solidly in the green despite some painful wobbles during the day, one sector was a notable laggard: the same sector that had dramatically outperformed the S&P since memory prices soared last October: memory stocks, most notably MU and SNDK.
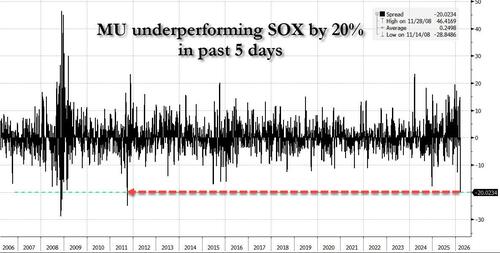
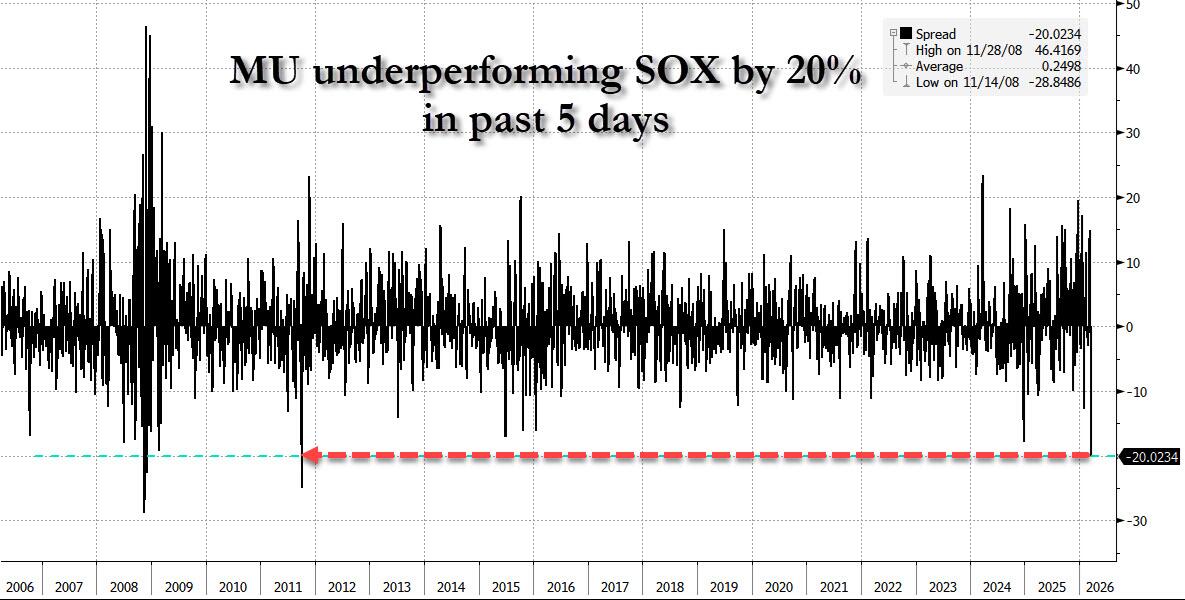
In his EOD wrap, Goldman tech specialist Peter Callahan wrote that while there wasn’t that much actual “angst” out there, his clients complained of plenty of “sanity checking” on the sharp downward moves in memory stocks (MU / SNDK lower vs. OEMs higher) and especially “the 5 day slide in MU as Micron has underperformed the SOX by 20% in 5-days, starting with the company’s blowout earnings report; that move ranks as the largest 5 days of underperformance relative to Semis/SOX since 2011.
{kind=link}
What caused today’s remarkable slump, which at one point saw Micron shares fall over 6% and Sandisk sliding 9% before paring losses, with other notable decliners including Western Digital (-6.7%) and Seagate Technologies (-8.5%)?
The answer was the latest announcement from Google Research, which after the close on Wednesday unveiled TurboQuant, a compression algorithm for large language models and vector search engines, that shrinks a major inference-memory bottleneck: it reduces an AI model’s memory 6x, making it 8x faster with the same number of GPUs, all the while maintaining zero loss in accuracy and “redefining AI efficiency.”
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc pic.twitter.com/9SJeMqCMlN
— Google Research (@GoogleResearch) March 24, 2026
The paper is slated for presentation at ICLR 2026, but the reaction online was immediate: Cloudflare CEO Matthew Prince called it “Google’s DeepSeek moment.“
To be sure, the announcement from @GoogleResearch generated massive engagement, with over 7.7 million views, signaling that the industry was hungry for a solution to the memory crisis. Everyone – except for the memory producers – was ecstatic.
Within 24 hours of the release, community members began porting the algorithm to popular local AI libraries like MLX for Apple Silicon and llama.cpp.
Technical analyst @Prince_Canuma shared one of the most compelling early benchmarks, implementing TurboQuant in MLX to test the Qwen3.5-35B model.
Across context lengths ranging from 8.5K to 64K tokens, he reported a 100% exact match at every quantization level, noting that 2.5-bit TurboQuant reduced the KV cache by nearly 5x with zero accuracy loss. This real-world validation echoed Google’s internal research, proving that the algorithm’s benefits translate seamlessly to third-party models.
Just implemented Google’s TurboQuant in MLX and the results are wild!
Needle-in-a-haystack using Qwen3.5-35B-A3B across 8.5K, 32.7K, and 64.2K context lengths:
→ 6/6 exact match at every quant level
→ TurboQuant 2.5-bit: 4.9x smaller KV cache
→ TurboQuant 3.5-bit: 3.8x… https://t.co/aLxRJIhB1D pic.twitter.com/drVrkL7Pw4
— Prince Canuma (@Prince_Canuma) March 25, 2026
Other users focused on the democratization of high-performance AI. @NoahEpstein_ provided a plain-English breakdown, arguing that TurboQuant significantly narrows the gap between free local AI and expensive cloud subscriptions.
He noted that models running locally on consumer hardware like a Mac Mini “just got dramatically better,” enabling 100,000-token conversations without the typical quality degradation.
Similarly, @PrajwalTomar_ highlighted the security and speed benefits of running “insane AI models locally for free,” expressing “huge respect” for Google’s decision to share the research rather than keeping it proprietary.
The implication is clear: if Google can achieve the same inference results with one-sixth of the hardware, then demand for memory chips will collapse in inverse proportion – the same ravenous demand that until recently sent DDR prices as much as 7x higher in just 3 months when the memory bottleneck for AI became apparent…
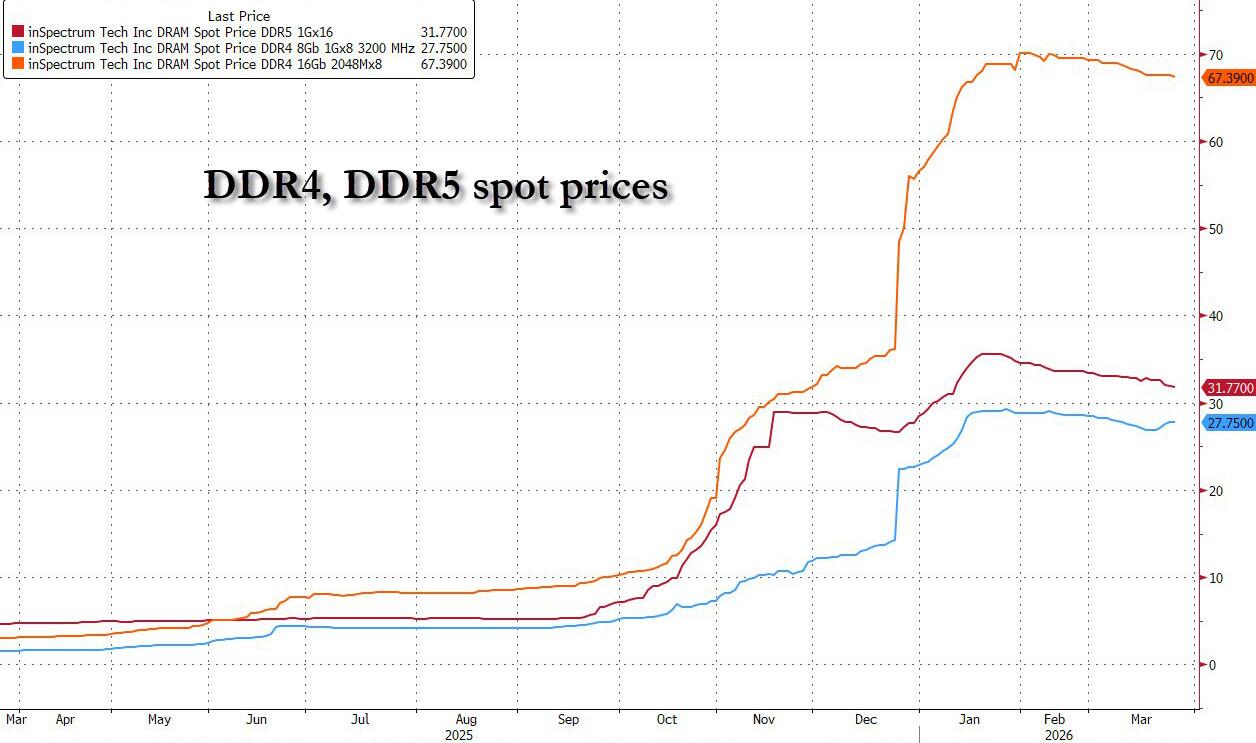{kind=link}
… and more recently sent inference-heavy NAND Flash prices also surging.
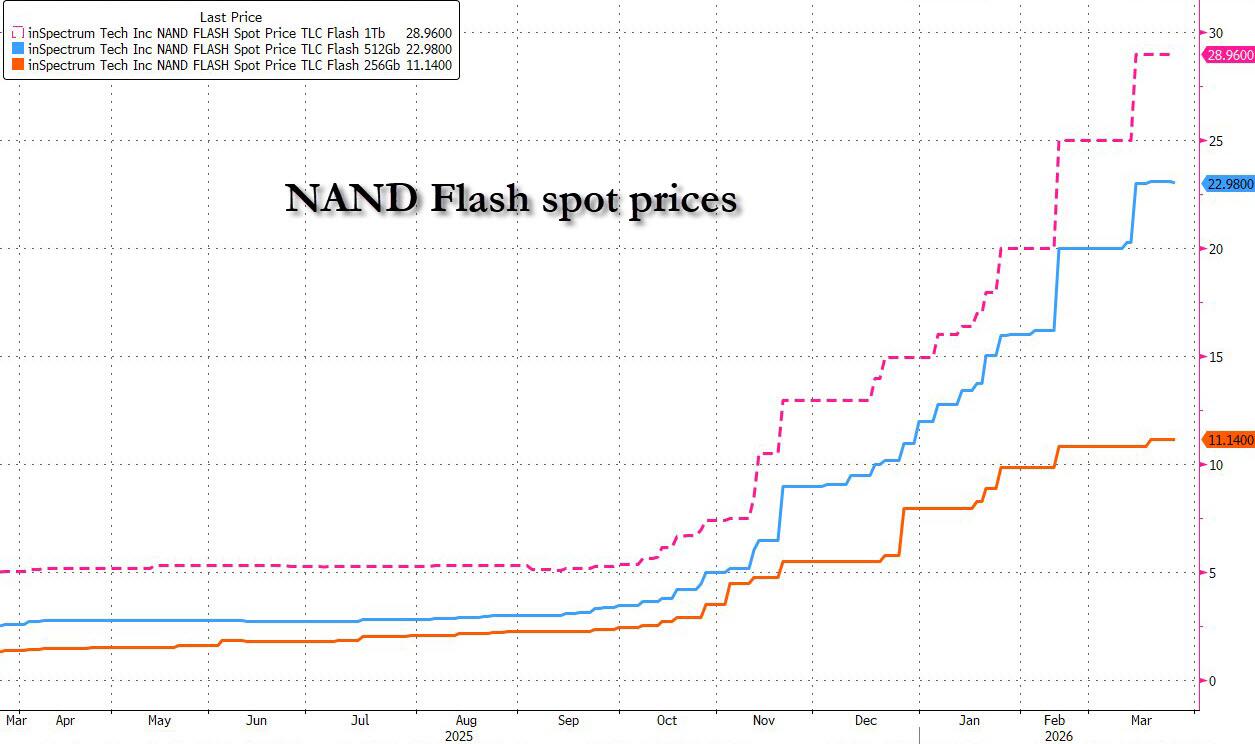{kind=link}
If this sounds similar to the infamous Pied Piper algorithm from Silicon Valley, it’s because it is, all minus the jerking off part :
Prominent cryptocurrency analyst Kaleo captured the sentiment perfectly, tweeting: “So Google TurboQuant is basically Pied Piper and just hit a Weismann Score of 5.2.” This reference to the fictional show’s compression metric demonstrates how deeply the cultural comparison has resonated. Technology commentator Justin Trimble echoed this perspective, simply stating: “TurboQuant is the new Pied Piper.”
Of course, that’s a bit hyperbolic, but the premise is there: taking existing hardware and achieving a far better compression result.
A quick technical side note on how Turboquant achieves this remarkable improvement in efficiency per decrypt:
Quantization efficiency is a big achievement by itself. But “zero accuracy loss” needs context. TurboQuant targets the KV cache—the chunk of GPU memory that stores everything a language model needs to remember during a conversation.
As context windows grow toward millions of tokens, those caches balloon into hundreds of gigabytes per session. That’s the actual bottleneck. Not compute power but raw memory.
Traditional compression methods try to shrink those caches by rounding numbers down—from 32-bit floats to 16, to 8 to 4-bit integers, for example. To better understand it, think of shrinking an image from 4K, to full HD, to 720p and so. It’s easy to tell it’s the same image overall, but there’s more detail in 4K resolution.
The catch: they have to store extra “quantization constants” alongside the compressed data to keep the model from going stupid. Those constants add 1 to 2 bits per value, partially eroding the gains.
TurboQuant claims it eliminates that overhead entirely.
It does this via two sub-algorithms. PolarQuant separates magnitude from direction in vectors, and QJL (Quantized Johnson-Lindenstrauss) takes the tiny residual error left over and reduces it to a single sign bit, positive or negative, with zero stored constants.
The result, Google says, is a mathematically unbiased estimator for the attention calculations that drive transformer models.
In benchmarks using Gemma and Mistral, TurboQuant matched full-precision performance under 4x compression, including perfect retrieval accuracy on needle-in-haystack tasks up to 104,000 tokens.
For context on why those benchmarks matter, expanding a model’s usable context without quality loss has been one of the hardest problems in LLM deployment.
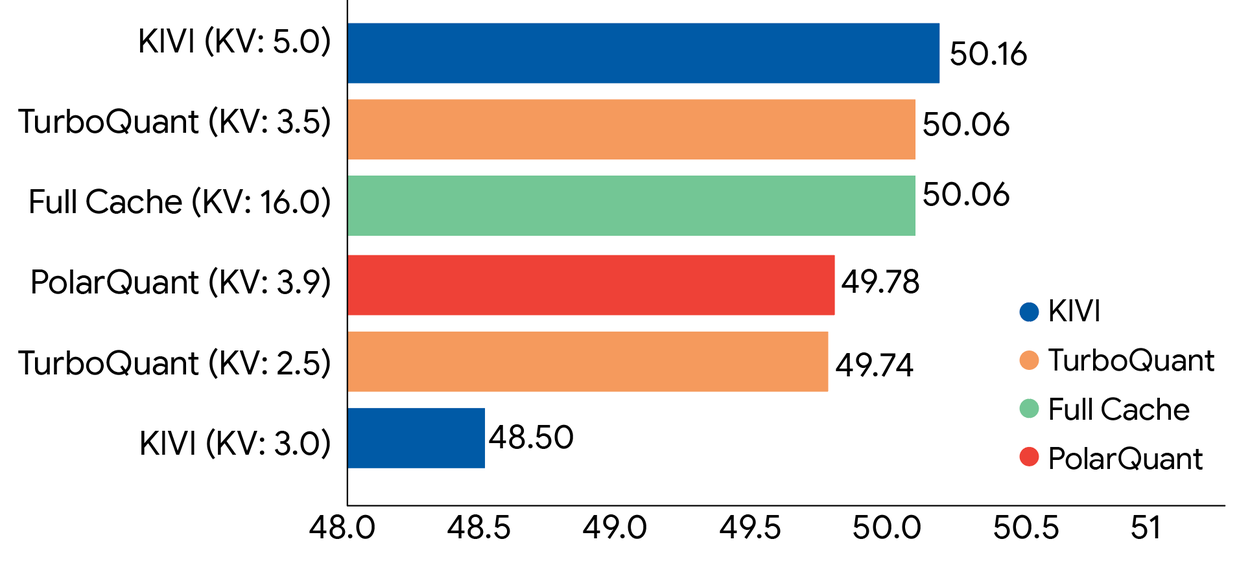{kind=link}
Now, the fine print. “Zero accuracy loss” applies to KV cache compression during inference—not to the model’s weights. Compressing weights is a completely different, harder problem. TurboQuant doesn’t touch those.
What it compresses is the temporary memory storing mid-session attention computations, which is more forgiving because that data can theoretically be reconstructed.
There’s also the gap between a clean benchmark and a production system serving billions of requests. TurboQuant was tested on open-source models—Gemma, Mistral, Llama—not Google’s own Gemini stack at scale.
The punchline: unlike DeepSeek’s efficiency gains, which required deep architectural decisions baked in from the start, TurboQuant requires no retraining or fine-tuning and claims negligible runtime overhead. In theory, it drops straight into existing inference pipelines.
That’s the part that spooked the memory hardware sector – because if it works in production, every major AI lab will run much leaner on the same GPUs they already own. Or said, in terms of P&L, AI companies – already deeply cash flow negative – and which are suddenly bleeding even more profit margin (which they don’t have but assume they did) to soaring RAM prices, have found a software way to require far less hardware – potentially as much as 6x less – and thus flip the table on the memory makers who are generating massive profits precisely because they refuse to produce more memory in what some would call cartel-like behavior. In doing so, they may have eliminated the entire physical memory bottleneck, courtesy of the memory cartel which magically can’t find any new supply until 2027 or later.
But wait, it gets better: because if Google has already found a compression algo that achieves such phenomenal efficiency improvements, it is virtually certain that further optimization – and competing algos – will surely lead to far greater efficiency, reducing the amount of hardware needed even further.
And just like that, suddenly the memory bubble which was built on the assumption that demand for DRAM and NAND will persist will into the future, looks set to burst as software may have just solved a very sticky hardware problem.
Indeed today’s plunge in stocks may have been just the first step. The market’s reaction reflects a realization that if AI giants can compress their memory requirements by a factor of six through software alone, the insatiable demand for High Bandwidth Memory (HBM) may be tempered by algorithmic efficiency.
As we move deeper into 2026, the arrival of TurboQuant suggests that the next era of AI progress will be defined as much by mathematical elegance as by brute force. By redefining efficiency through extreme compression, Google is enabling “smarter memory movement” for multi-step agents and dense retrieval pipelines. The industry is shifting from a focus on “bigger models” to “better memory,” a change that could lower AI serving costs globally.
Ultimately, TurboQuant proves that the limit of AI isn’t just how many transistors we can cram onto a chip, but how elegantly we can translate the infinite complexity of information into the finite space of a digital bit. For the enterprise, this is more than just a research paper; it is a tactical unlock that turns existing hardware into a significantly more powerful asset.
The Google paper goes to ICLR 2026. Until it ships in production, the “zero loss” headline stays in the lab, but the market isn’t waiting and the mere threat that demand for memory may tumble by orders of magnitude could shock the entire ecosystem. In which case, buy puts on the Kospi, which is about 100% overvalued if the “memory benefit” of its two core stocks, Samsung and SK Hynix, disappears. Come to think of it, short everything memory.
For more, please see “Google’s new TurboQuant algorithm speeds up AI memory 8x, cutting costs by 50% or more“
Tyler Durden
Wed, 03/25/2026 – 21:45